
Text-to-image diffusion generative models can generate high quality images at the cost of tedious prompt engineering. Controllability can be improved by introducing layout conditioning, however existing methods lack layout editing ability and finegrained control over object attributes. The concept of multi-layer generation holds great potential to address these limitations, however generating image instances concurrently to scene composition limits control over fine-grained object attributes, relative positioning in 3D space and scene manipulation abilities. In this work, we propose a novel multi-stage generation paradigm that is designed for fine-grained control, flexibility and interactivity. To ensure control over instance attributes, we devise a novel training paradigm to adapt a diffusion model to generate isolated scene components as RGBA images with transparency information. To build complex images, we employ these pre-generated instances and introduce a multilayer composite generation process that smoothly assembles components in realistic scenes. Our experiments show that our RGBA diffusion model is capable of generating diverse and high quality instances with precise control over object attributes. Through multi-layer composition, we demonstrate that our approach allows to build and manipulate images from highly complex prompts with finegrained control over object appearance and location, granting a higher degree of control than competing methods.
A few modifications were made to the PixArt-Alpha VAE to make it compatible with RGBA images. Firstly, the additional channel is simply taken into account by replacing and retraining the input and output layers of the model. Secondly, we observed that learning a joint RGBA latent space leads to entanglement of RGB and alpha channels, affecting generation capability of diffusion models trained in this latent space. We address this challenge by disentangling representations in the latent space: our VAE predicts two separate distributions [EQ1] and [EQ2], each associated with a separate KL loss.
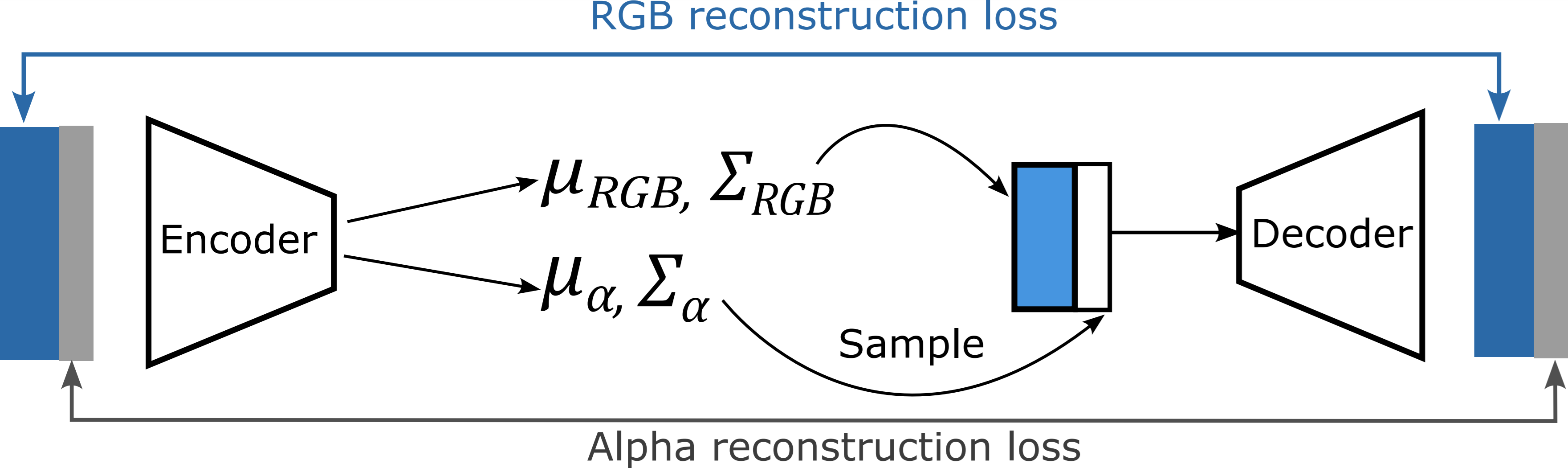
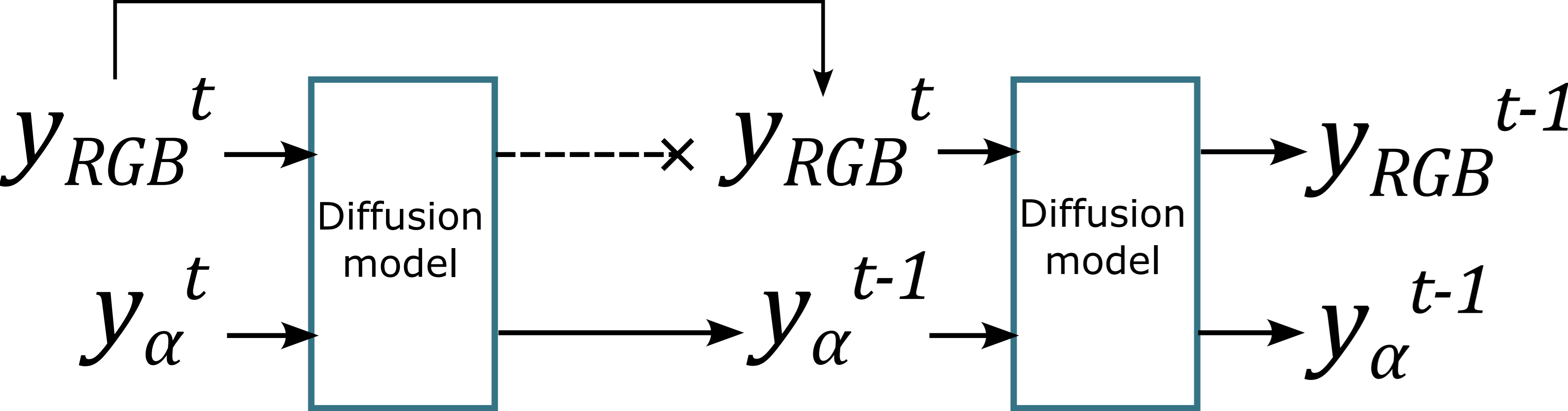
In our case, the latent space also encodes information on the transparency layer. When sampling from our model, we seek to exploit the mutual dependency between RGB and alpha channels. In particular, given RGB and Alpha noised latents at timestep t, information contained in the RGB noised latents at timestep t-1 could be employed to inform the Alpha noised latents update from timestep t to t-1.
We can observe that our approach is able to generate realistic instances following the instructions given. Text2Layer shows lower image quality and excessive transparency, while LayerDiffusion struggles to follow prompt details, such as image style. Combining SD with Matting allows to achieve reasonable segmentation of the instances generated, while when applied to PixArt-α it can sometimes struggle to correctly identify and segment the main object of the image, especially when dealing with artwork content. On top of attributes bleeding in the background, this highlights how unreliable matting can be for instance generation purposes.

We consider that we have an image layout available, and generated instances based on our RGBA generator. The layout is represented by a collection of bounding boxes. Our scene composition approach is designed as a multi-layer noise blending process, where instances are sequentially integrated into intermediate layered representations. While we generate K+1 images, where K is the number of instances and we also account for the background, we observed that generating layered images affords more flexibility, better control over relative positions of instances and yields more natural compositions.
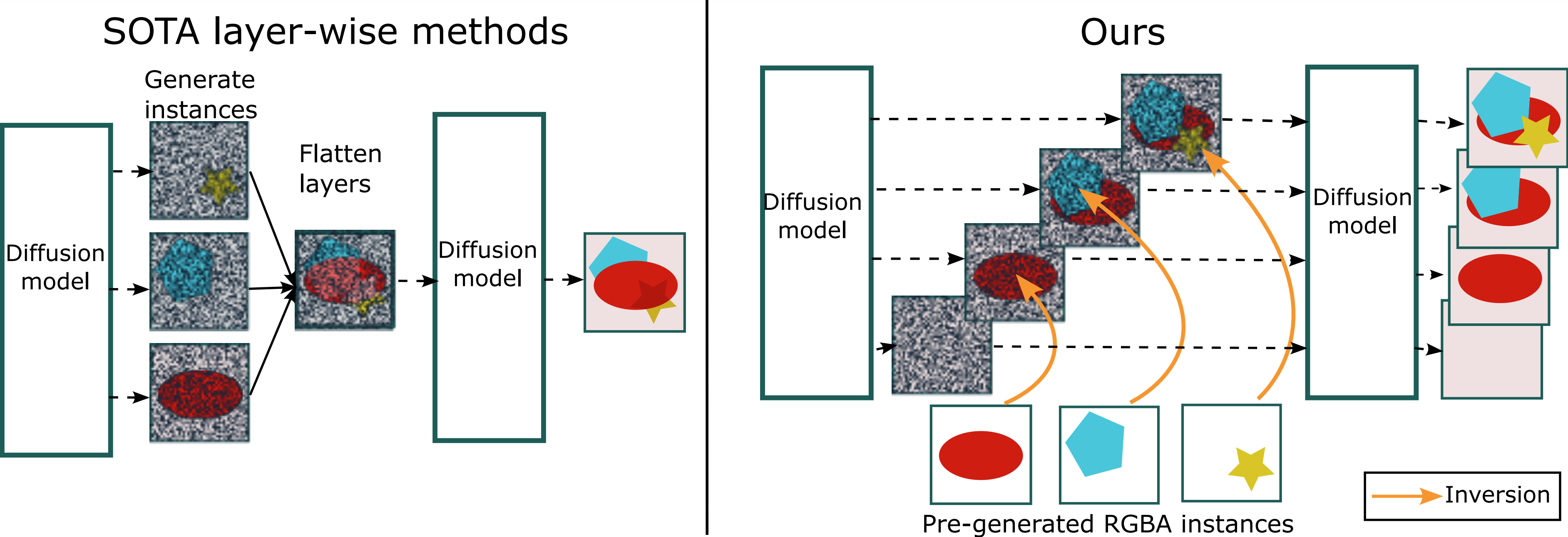
While GLIGEN is capable of accurately reproducing the desired layout, it often fails to assign the right attributes to objects and struggles with highly overlapping objects. In contrast, Multidiffusion is more accurate in terms of attribute assignments, but struggles to handle overlapping objects. This can be attributed to the noise averaging process, which fails to integrate a notion of instance ordering like our multi-layer approach. Instance diffusion achieves performance closest to ours, but still struggles with complex patterns, attributes and relative positioning. With our RGBA instance generation and multi-layer noise blending, we are able to accurately assign object attributes and follow the required layout, while successfully building smooth and realistic scenes.

The manipulations we consider here are: attribute modification, instance replacement, and layout adjustment. We note that the first two tasks require RGBA generation of new instances. We highlight that we do not introduce any new explicit scene preservation or image editing technology in this experiment, therefore evaluating our method’s potential for scene manipulation and controllability. We are able to control and modify image content easily while maintaining strong consistency across different versions of the scene, without explicitly enforcing content preservation. This highlights the strong potential of multi-layer approaches to facilitate the development of image editing methods. We can see that we achieve substantially stronger scene preservation compared to instance diffusion, which can generate entirely different images and instances when modifications are too strong.

@inproceedings{
Fontanella_NeurIPS_2024_RGBA_Scene,
title = {Generating compositional scenes via Text-to-image {RGBA} Instance Generation},
author = {Alessandro Fontanella and Petru-Daniel Tudosiu and Yongxin Yang and Shifeng Zhang and Sarah Parisot},
booktitle = {The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year = {2024},
url = {https://openreview.net/forum?id=MwFeh4RqvA}
}


























